On CMS open data, and numbers big and small
In July 2021, the open data group of the CMS experiment conducted the second CMS open data workshop aimed at physicists interested in research use of these unique public data. In the spirit of openness, the number of registrants was not restricted, and the workshop was actively followed by some 50 participants with diverse backgrounds and origins.
The event was four full days of work, preceded by a set of pre-exercises to be completed before the start. The workshop aimed to cover the skills needed to get started with the experimental particle physics data from the CMS experiment, and all exercises were hands-on. A session practising running CMS data analysis jobs in a cloud computing environment was included. The feedback survey indicates that the workshop was a success: the participants gained confidence in using these data and would recommend the workshop for colleagues with similar interests.
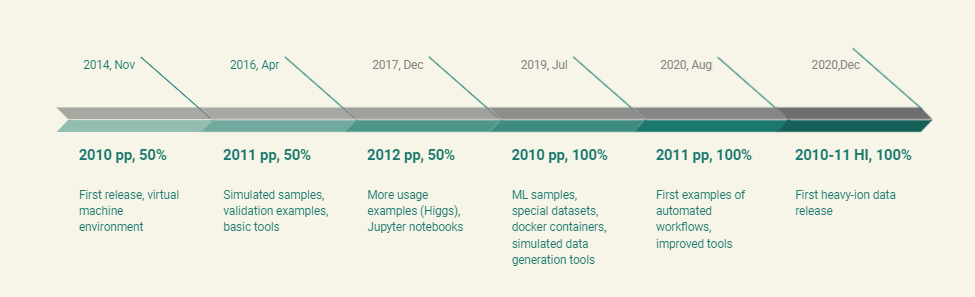
I have been involved in CMS data preservation and open data activities right from the beginning. In 2011, I chaired the working group set up to draft the CMS data preservation, re-use and open access policy, the first of its type in particle physics, and since 2012, I’ve been leading the group that was created to implement the policy after its approval. It is tempting for me to reflect on the evolution in these ten years. Figure 1 shows the timeline of the data releases, which now include most of the Run-1 data (collected in 2010-2012). The first Run-2 data releases of data collected in 2015-2018 are in preparation.
In the drafting of the data policy, I remember well Jesus Marco from Universidad de Cantabria, a member of the data policy working group, proposing that CMS should promote a workshop after the first release to assess whether these data can be usefully exploited by people external to the CMS collaboration. At that time, the concept of open data in particle physics was totally new and even terrifying for many, and organising a workshop on their use certainly sounded rather distant wishful thinking. The proposal, however, boldly made its way to the policy document, and now, ten years after, we are collecting feedback from the participants of the second workshop of this type.
To be able to call the first open data workshops took us several data releases, with gradual and continuous improvements of the accompanying material. For data to be usable, much more is required than public access to them. Data management and re-usability are often described with FAIR principles for Findable, Accessible, Interoperable, and Re-usable data and metadata, i.e. “data about data”. CMS data released through the CERN open data portal satisfy these principles to a large extent. But due to the complexity of experimental particle physics data, the FAIR principles alone do not guarantee the re-usability of these data, and additional effort is needed to pass on the knowledge needed to use and interpret them correctly.
This knowledge includes, first of all, learning the computing environment and software for the first step of data selection. Due to the experiment-specific data format, the first step will almost inevitably be done using the CMS software in a computing environment compatible with the open data. We have been able to benefit from the advance of software containers such as Docker with which we have packaged the CMS software that is required and virtualised the operating system compatible with it. Open data users can download a software container image and run it on their computer, independently of its operating system. Recent developments for Windows Subsystem Linux (WSL2) have also made this feasible in Windows, in addition to Linux and macOS. The CMS open data group has invested a good amount of work in setting up these containers so that the first user experience with the CMS open data remains smooth. It is important to remember that open data users always start with a trial: if they consider that the time needed to overcome difficulties is too much, they will just give up.
After having set up the computing environment, open data users will need to learn the intricacies of experimental particle physics data. How to select the data of interest, how to identify the particles properly, how to understand the efficiencies and uncertainties in the analysis process, how to estimate the backgrounds, and how to address many other challenges with experimental data. This is all brilliantly summarised in the blog posting “The Importance and Challenges of “Open Data” at the Large Hadron Collider” by Matt Strassler who with Jesse Thaler has provided valuable feedback while pioneering the use of CMS open data.
But how come collecting the necessary information has taken so long? Having well over 1000 high-quality scientific publications on CMS data we must know the tiniest details of these data and have well-established procedures for their analysis. Why just not release these guidelines with the data? The challenge is in the size, and I’m not referring to data volumes. In his popular book “The tipping point”, Malcolm Gladwell discusses Dunbar’s number, first proposed by anthropologist Robert Dunbar in the 1990s. This is a suggested limit to the maximum number of individuals with whom an animal can maintain group cohesion and social relationships by personal contact, often cited to be around 150 for humans. Gladwell gave examples of organisations that have successfully limited the number of people in a single establishment or production unit to that number, for efficient work organisation and the wellbeing of people. Dunbar argues that at this size, groups function based on common loyalty and cohesion, with direct person-to-person interactions.
But in big scientific collaborations, there are many more of us. Of over 4000 members of the CMS collaboration, close to 3000 are physicists, most of them active in analysing the data. Work is carried out in physics analysis groups and their subgroups in which the number of people involved is indeed within the limits of estimated Dunbar’s number. This is an obvious working mode, grouping people around similar topics. However, this results in working procedures that diverge within the collaboration. Much effort goes to the development of individual or group-specific software and procedures, while contributions to the software common to the entire collaboration are often lacking. A layer of group or topic-specific software is naturally needed, but the thickness of that layer increases if measures are not taken to counterbalance this drift. Figure 2 illustrates my simplified perception of the data and software landscape in a big collaboration such as CMS. The green arrows indicate the phases in the data analysis process in which each individual or group-specific software most likely implement the same or similar steps. The CMS collaboration has taken measures to address these problematics, through the adoption of slimmer data formats in which a part of the common procedures has already been implemented and by setting up a reflection group on common software tools. I argue that strong and continuous action will always be needed to encourage contributions for the common good of the full collaboration, to compensate for the human tendency of working comfortably in much smaller units. Writing software in a way that benefits everyone in the collaboration should be perceived as a common goal in every group.
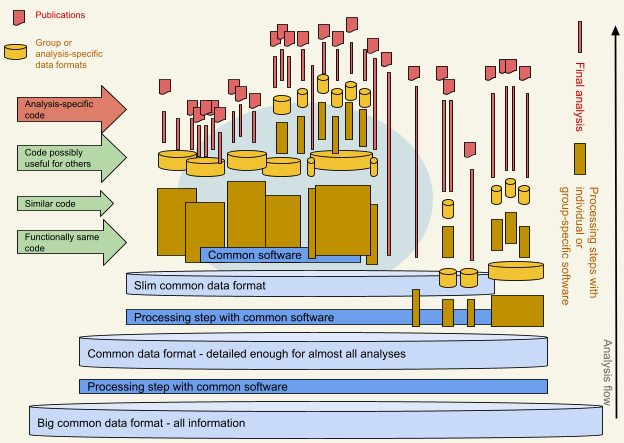
From the point of view of open data, the abundance of group-specific data “skims” and software frameworks makes it challenging to come up with generic examples and instructions applicable to public datasets for open data users. We can find code examples within one software framework in use for the analysis of certain physics topics with topic-specific skimmed datasets as input. However, another physics group may use a different implementation of the same analysis steps in their software package. Collecting this knowledge from different sources, indicated with a light blue background colour in Figure 2, is not an obvious task. The open data workshops and the general interest in CMS open data have been a great motivation for this effort, and the CMS open data team has now put together a comprehensive set of tutorials using an example code written for this purpose.
I firmly believe that the experience we are gaining in improving the usability of CMS open data can feedback to the collaboration. During these workshops, we have initiated participants in the use of CMS software using Docker containers. We have found solutions for many common issues, such as opening graphic windows, copy-pasting, passing files between the container and host, etc., i.e., many of those details that determine how efficiently one can work. For many of us, container solutions have turned out to be a practical tool for everyday work. We have also exercised running the analysis jobs in a cloud environment and demonstrated the value of well-defined machine-readable workflows.
I am also convinced that our observations on the difficulty of finding comprehensive examples of basic open data usage with common software are relevant not only to open data but also to the analysis work done in the collaboration. For the efficient use of human resources, I would argue that the questions to be asked before writing new analysis software should be 1) can this be done with software tools available to everyone in the collaboration 2) if this cannot be done with existing, common tools, would a contribution to them be more appropriate than writing a separate piece of software 3) can this be made configurable so that it can be used for other similar use cases 4) can this be reused. This is what is needed to preserve the knowledge inherent in the analysis work so that it remains usable – and not only readable – for immediate use by the collaborators beyond the first small reference group, and into the longer-term future. To make this happen in large collaborations, to counterbalance the human preference of acting to the benefit of the small working unit, the contributions to the common tools need to be actively encouraged and promoted in everyday work and valued in career assessments.
Helsinki Institute of Physics: Helsinki Institute of Physics (HIP) is a strong contributor to the CMS open data project. In addition to the author, the coordinator of the CMS data preservation and open access group, several students and trainees have participated in the activities. HIP’s “Open data and education” project is an important stakeholder for the usability of these data in secondary education.
Kati Lassila-Perini
Project Leader, Education and Open Data
Helsinki Institute of Physics